经过差不多两个月的重构,在社区小伙伴的共同协作努力下,LotusDB V2.0.0版本正式发布!
LotusDB 项目地址:https://github.com/lotusdblabs/lotusdb
LotusDB 是用 Go 语言编写的 KV 数据库,它采用 KV 分离的思想,融 LSM Tree 和 B+ Tree 存储模型为一体,适合大规模的 KV 数据存储,相较于 Go 语言领域知名的 KV 存储项目 badger 和 bbolt,LotusDB 具有更先进的设计架构。
这次我们通过两个月的重构,将 LotusDB 原来 V1 版本的代码基本上重新实现了一遍,目的在于提高简洁度。
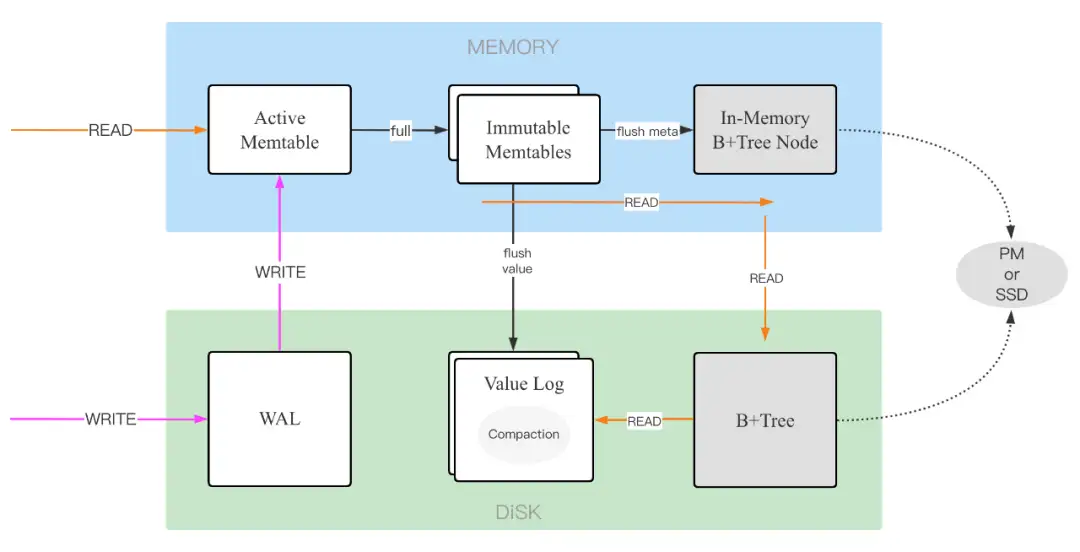
LotusDB 的整体架构实现了全新升级,目的在于提升读写和压缩性能,下面是之前 V1 版本的架构图:
这是重构后的 V2 版本的架构图:
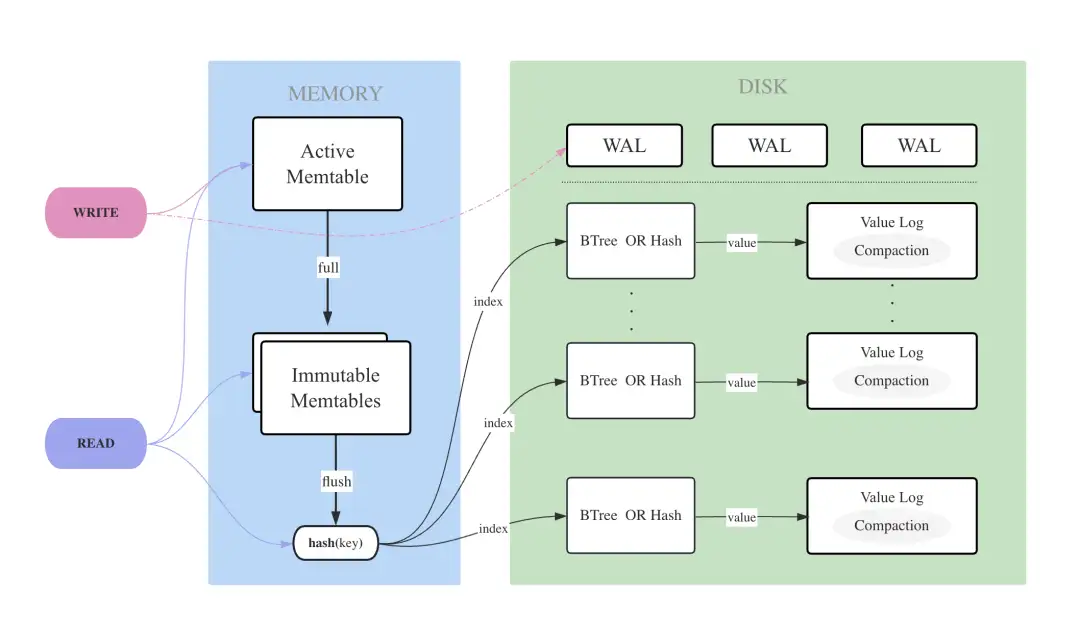
相对于 V1 版本,V2 版本主要有以下更新:
- 新版本的所有磁盘存储(包括预写日志 WAL 和 Value Log)均直接采用 wal 组件(https://github.com/rosedblabs/wal)实现,代码屏蔽了底层管理文件读写的操作,更加简洁易懂
- 新版本通过对 key 哈希分片的方式构建多个 Index 和 Value Log 对象,实现了 Index 和Value Log 的并发读写,读写和压缩性能相对于 V1 提升了 2~3 倍,这也是本次重构架构上最大的更新
- TODO:另一大重要更新是将会引入新的基于磁盘的 Hash 索引,这样 LotusDB 将会支持磁盘 BTree 和 Hash 两种类型的索引,满足更多样化的场景(预计在下一次 Release 发布)
- 新版本舍弃了 Column Family(CF) 的设计,目的在于使架构更加简洁,原来跨 CF 的操作并不能保证原子性,如果后续有需求的话将会重新设计这个 feature
毫不夸张的说,这是目前 Go 语言领域架构最先进的 KV 存储引擎项目,其优势主要体现在:
- 结合了 LSM 和 B+ 树存储模型的优点,B+ 树读性能稳定,而 LSM 写吞吐高,LotusDB 在这基础上做了一个巨大的改动,就是采用 KV 分离的思想,完全舍弃掉 LSM 中的 SST 文件,改由 B+ 树来存储索引,而 value 存放则参考了 Wisckey 和 bitcask 模型的设计,以追加写的方式存储到单独的 value log 文件中,充分利用顺序 IO 的优势
- 更加均衡和快速的读/写性能,写入 LotusDB 的数据不需要在磁盘上排序,追加写的 Value Log 设计在写入过程中减少了磁盘磁头的移动,因此即便是完全无序的数据,LotusDB 依然能够保持较高的吞吐量。同时 LotusDB 的读写性能更加均衡,而不会像bbolt 那样读写性能差距极大,适合读写都非常频繁的业务场景
- 比典型的 LSM 低得多的读放大,LotusDB 采用 KV 分离的思路,从 B+ 树中获取 Key 对应 Value 在磁盘中的存储地址后,即可直接一步读取 Value 数据,显著降低了传统 LSM 存储模型带来的读放大问题
- 更大规模的数据存储,和 LotusDB 的姊妹项目 RoseDB 相比,LotusDB 是一个基于磁盘索引的 KV 存储引擎,而 RoseDB 是 Bitcask 存储模型全内存索引,因此数据存储规模基本不受到内存大小的影响,因此更加适合大规模的数据存储
- 支持崩溃恢复,LotusDB 实现了 WAL 机制,在将 KV 数据刷盘前就将事务日志进行持久性存储,数据库崩溃后依然能够从 WAL 中读取事务日志,保证事务的原子性
- 数据并发式刷盘 LotusDB 通过将 key 进行哈希分片的机制,建立多个 Index 和 Value Log 对象,每一组 Index & Value Log 对象对应一个数据片,当 memory table 中的数据需要刷盘时,多个对象可以通过并发的方式实现刷盘,大大提升了刷盘的吞吐量
以下是 LotusDB 的简单使用示例,大家可以上手体验!
| |
致谢
在 LotusDB 的重构过程中,非常感谢社区的各位小伙伴的参与和积极贡献,特别是 @燕小七 和 @akiozihao 表现最为积极活跃,为 LotusDB 2.0 的重构做了很多工作,再次表示感谢,也希望能够继续参与。
同时 @燕小七 同学成为了 LotusDB 的第一位 Committer,后续我们希望能够培养更多的 Committer 和 Maintainer,充分发挥社区的作用,共同打造和完善 LotusDB 这个最先进的 KV 存储引擎!
同时也非常欢迎大家能够参与进来,目前我们只是发布了第一个版本,后续将会持续迭代,能够让大家发挥的空间巨大,感兴趣的可以加我微信私聊,我会将你拉到开发者群当中。