前面一节说到,在 Postgres 的 VFD 机制之上,我们可以避开打开文件数量的系统限制,通过 VFD 可以进行打开、读写、关闭、删除文件等操作,简单来说就是 VFD 为我们提供了一个抽象,屏蔽了操作系统文件描述符的接口,后续我们对文件的 open、close,以及 CRUD 操作都在 VFD 的基础之上。
文件类型和文件块
要了解 Postgres 的存储管理,需要先对 Postgres 的表文件的组织方式、类型有一个简单的了解。
Postgres 中的表文件可能会非常大,在物理存储上会将表文件拆分为多个,每一个表文件通过 segno 来区分。
在 Postgres 的数据目录中,表文件的存储格式为 base/<database oid>/<table relfilenode>。
在 base 目录下,存储了不同 Database 的数据,例如在我的当前环境中,当前的数据库名为 rose,其 oid 为 24582。
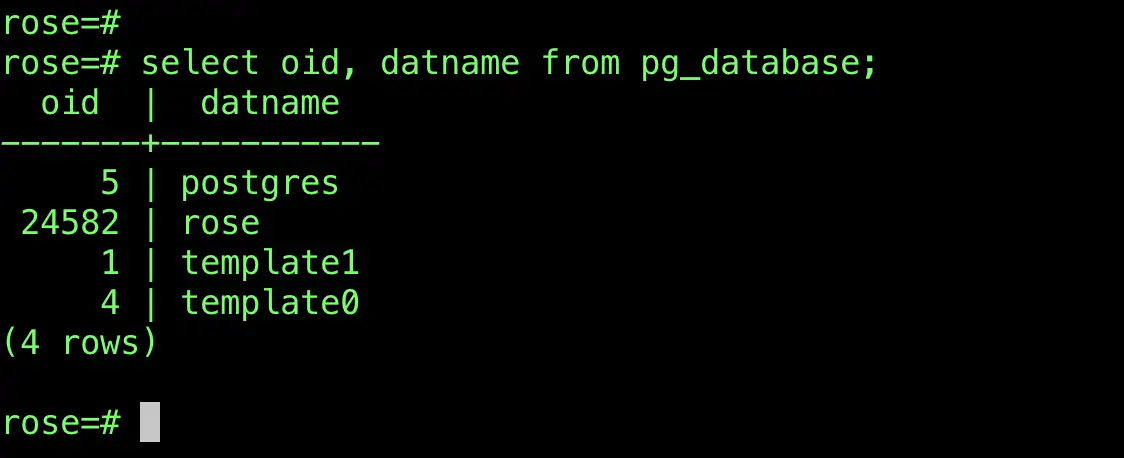
所以在 Postgres 数据目录的 base 目录下,就会有对应的 Database 目录,目录名称就是 Oid:
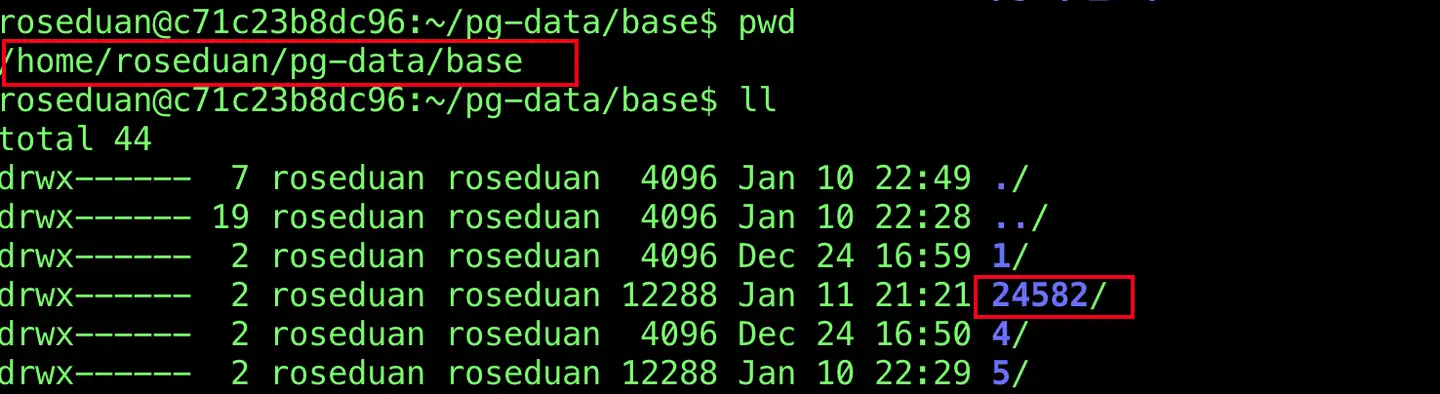
我在当前数据库中有一个表,其名为 articles,我们可以通过 pg_class 表查询到对应的表 relfilenode。
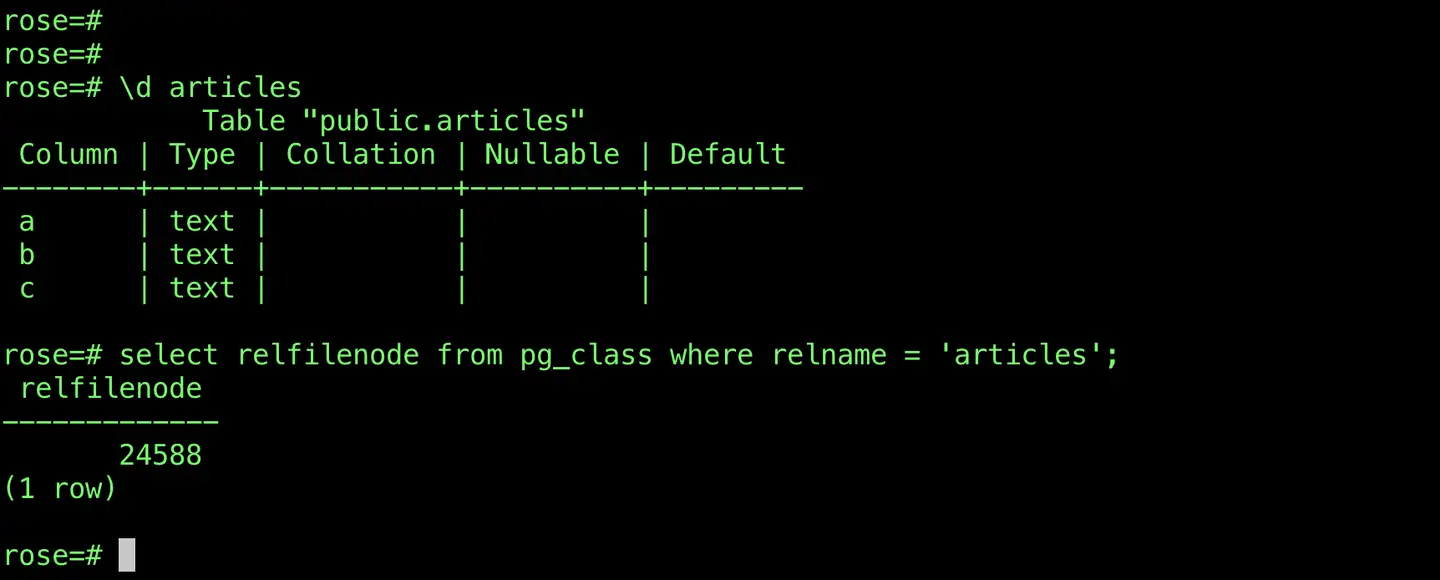
可以看到表对应的 relfilenode 是 24588,所以可以到 24582 这个数据库目录中,查看所有表数据相关的文件:
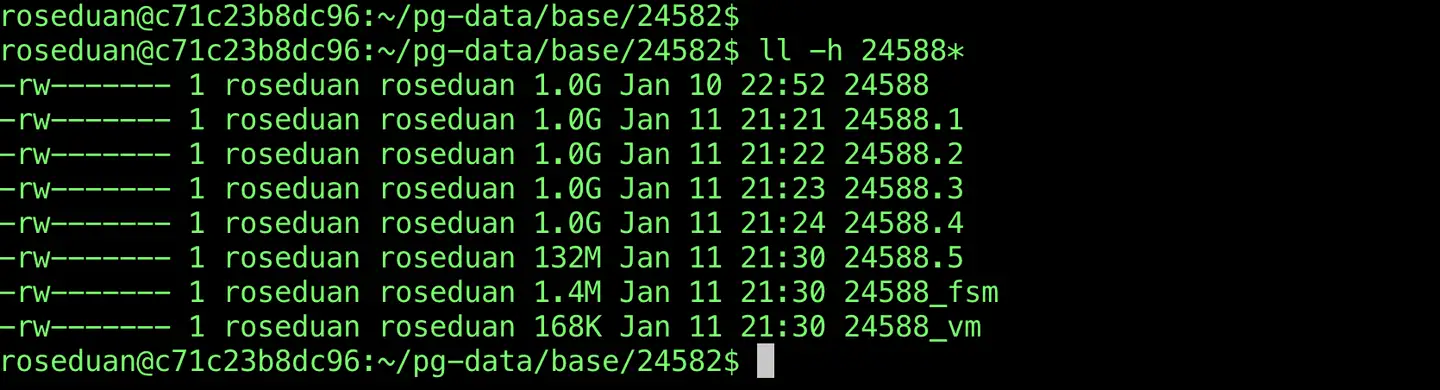
img
可以看到表数据文件被分为了
24588
24588.1
24588.2
24588.3
24588.4
24588.5
每一个数据文件被称为一个数据段(Segment)文件,符号 . 后就是段号(segno),第 0 个分段文件没有段号。
除了数据文件,还有 24588_fsm 表示的是表的空闲空间映射文件,记录每个文件的空闲空间大小,24588_vm 即 VisibilityMap 文件,记录的是每个文件页的可见状态。
在源码中,定义了枚举 ForkNumber 来表示每种文件的类型。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| /*
* Stuff for fork names.
*
* The physical storage of a relation consists of one or more forks.
* The main fork is always created, but in addition to that there can be
* additional forks for storing various metadata. ForkNumber is used when
* we need to refer to a specific fork in a relation.
*/
typedef enum ForkNumber
{
InvalidForkNumber = -1,
MAIN_FORKNUM = 0,
FSM_FORKNUM,
VISIBILITYMAP_FORKNUM,
INIT_FORKNUM,
/*
* NOTE: if you add a new fork, change MAX_FORKNUM and possibly
* FORKNAMECHARS below, and update the forkNames array in
* src/common/relpath.c
*/
} ForkNumber;
|
MAIN_FORKNUM:表数据文件
FSM_FORKNUM:空闲空间映射文件
VISIBILITYMAP_FORKNUM:文件页可见性
INIT_FORKNUM:主要用于 UNLOGGED 表
在分配和读取数据文件的时候,为了效率,一般会以块为单位, 在 Postgres 中默认块大小是 8KB,可以在系统初始化时设置。
1
2
3
4
5
6
7
8
| /* Size of a disk block --this also limits the size of a tuple. You can set
it bigger if you need bigger tuples (although TOAST should reduce the need
to have large tuples, since fields can be spread across multiple tuples).
BLCKSZ must be a power of 2. The maximum possible value of BLCKSZ is
currently 2^15 (32768). This is determined by the 15-bit widths of the
lp_off and lp_len fields in ItemIdData (see include/storage/itemid.h).
Changing BLCKSZ requires an initdb. */
#define BLCKSZ 8192
|
还有另一个参数是 RELSEG_SIZE,表示一个文件中的最大块数量,使用这个参数和 BLOCKZ,就能够计算出每个数据文件的最大值,目前默认是 1GB(131072 * 8192 / 1024 / 1024 / 1024 = 1GB)。
1
2
3
4
5
6
7
8
9
10
11
12
| /* RELSEG_SIZE is the maximum number of blocks allowed in one disk file. Thus,
the maximum size of a single file is RELSEG_SIZE * BLCKSZ; relations bigger
than that are divided into multiple files. RELSEG_SIZE * BLCKSZ must be
less than your OS' limit on file size. This is often 2 GB or 4GB in a
32-bit operating system, unless you have large file support enabled. By
default, we make the limit 1 GB to avoid any possible integer-overflow
problems within the OS. A limit smaller than necessary only means we divide
a large relation into more chunks than necessary, so it seems best to err
in the direction of a small limit. A power-of-2 value is recommended to
save a few cycles in md.c, but is not absolutely required. Changing
RELSEG_SIZE requires an initdb. */
#define RELSEG_SIZE 131072
|
存储管理器
在 Postgres 中,在对表文件管理和操作时,提供了存储管理器(SMGR)的抽象,由于历史原因,早期的系统中,可能存在不同的存储系统,比如磁盘(magnetic disk)、索尼光盘(Sony WORM optical disk jukebox)、持久化主存(persistent main memory)等。
但是目前在操作系统层面,已经提供了文件系统的抽象,所以存储管理器其实已经没有存在的必要了,但是 Postgres 依然选择将其保留,主要是认为这层抽象并没有什么其他的影响。
所以目前只保留了基于磁盘的存储管理,实际上底层还是调用的操作系统的文件系统。
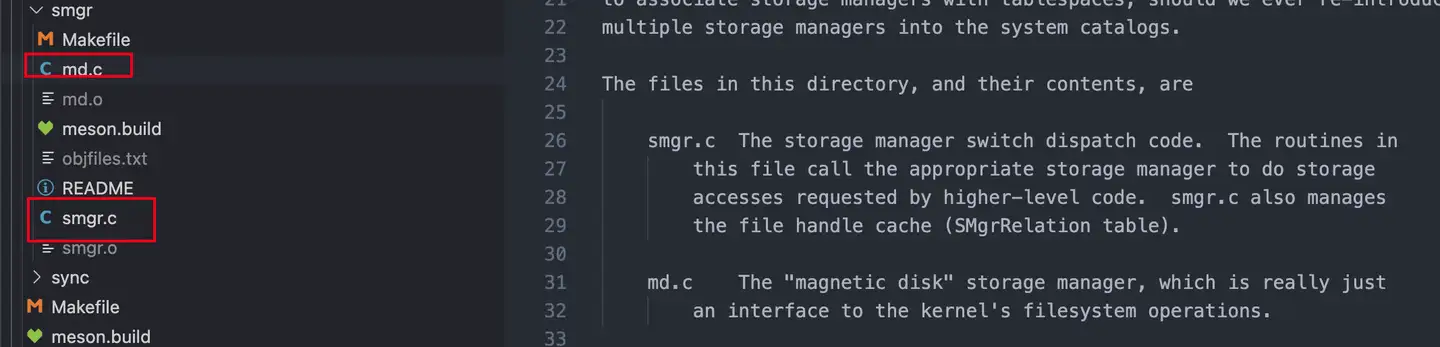
img
在源代码中也体现的很明显,两个文件,smgr.c 主要是存储管理器,而 md.c 就是磁盘的存储管理。
存储管理器类似一个顶层抽象,具体的存储管理操作都交给了磁盘存储管理器。
磁盘存储管理器
在 Postgres 中,一个表会有多个文件,对于表中打开的文件的管理,使用结构体 SMgrRelationData 来表示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
| /*
* smgr.c maintains a table of SMgrRelation objects, which are essentially
* cached file handles. An SMgrRelation is created (if not already present)
* by smgropen(), and destroyed by smgrclose(). Note that neither of these
* operations imply I/O, they just create or destroy a hashtable entry.
* (But smgrclose() may release associated resources, such as OS-level file
* descriptors.)
*
* An SMgrRelation may have an "owner", which is just a pointer to it from
* somewhere else; smgr.c will clear this pointer if the SMgrRelation is
* closed. We use this to avoid dangling pointers from relcache to smgr
* without having to make the smgr explicitly aware of relcache. There
* can't be more than one "owner" pointer per SMgrRelation, but that's
* all we need.
*
* SMgrRelations that do not have an "owner" are considered to be transient,
* and are deleted at end of transaction.
*/
typedef struct SMgrRelationData
{
/* rlocator is the hashtable lookup key, so it must be first! */
RelFileLocatorBackend smgr_rlocator; /* relation physical identifier */
/* pointer to owning pointer, or NULL if none */
struct SMgrRelationData **smgr_owner;
/*
* The following fields are reset to InvalidBlockNumber upon a cache flush
* event, and hold the last known size for each fork. This information is
* currently only reliable during recovery, since there is no cache
* invalidation for fork extension.
*/
BlockNumber smgr_targblock; /* current insertion target block */
BlockNumber smgr_cached_nblocks[MAX_FORKNUM + 1]; /* last known size */
/* additional public fields may someday exist here */
/*
* Fields below here are intended to be private to smgr.c and its
* submodules. Do not touch them from elsewhere.
*/
int smgr_which; /* storage manager selector */
/*
* for md.c; per-fork arrays of the number of open segments
* (md_num_open_segs) and the segments themselves (md_seg_fds).
*/
int md_num_open_segs[MAX_FORKNUM + 1];
struct _MdfdVec *md_seg_fds[MAX_FORKNUM + 1];
/* if unowned, list link in list of all unowned SMgrRelations */
dlist_node node;
} SMgrRelationData;
|
其中比较关键的字段有:
md_num_open_segs:记录每个 FORK 类型当前已经打开的文件数量
md_seg_fds:针对每个 FORK 类型打开文件的 VFD 信息
SMgrRelationData 会使用一个进程私有的哈希表来保存,每次需要打开一个表的文件时,可以首先从这个哈希表中查找,如果找到的话直接返回,这样同一个表只需要维护一个结构体即可,有利于保持对表文件操作的一致性。
哈希表的 key 是 SMgrRelationData 结构体的第一个属性 smgr_rlocator:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| typedef struct RelFileLocator
{
Oid spcOid; /* tablespace */
Oid dbOid; /* database */
RelFileNumber relNumber; /* relation */
} RelFileLocator;
/*
* Augmenting a relfilelocator with the backend ID provides all the information
* we need to locate the physical storage. The backend ID is InvalidBackendId
* for regular relations (those accessible to more than one backend), or the
* owning backend's ID for backend-local relations. Backend-local relations
* are always transient and removed in case of a database crash; they are
* never WAL-logged or fsync'd.
*/
typedef struct RelFileLocatorBackend
{
RelFileLocator locator;
BackendId backend;
} RelFileLocatorBackend;
|
smgr_rlocator 的类型是 RelFileLocatorBackend,locator 是一个三元组,分别是 <tablespaceid,database id,relation id>,backend 只对临时表有用,对普通表来说,其值一般是 -1。
在磁盘存储管理器中,其实主要就是对 SMgrRelationData 的管理,涉及到对其创建、打开、关闭、删除、扩展等操作。
创建表文件
在函数 mdcreate 中实现,一个数据表会有很多个数据文件,这里的创建表文件指的是传入给定的 tablespace id、database id、relation id,以及文件类型(ForkNumber),创建第一个物理文件,后续其他新的文件会在写入数据的时候动态扩展。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| TablespaceCreateDbspace(reln->smgr_rlocator.locator.spcOid,
reln->smgr_rlocator.locator.dbOid,
isRedo);
path = relpath(reln->smgr_rlocator, forknum);
fd = PathNameOpenFile(path, _mdfd_open_flags() | O_CREAT | O_EXCL);
if (fd < 0)
{
int save_errno = errno;
if (isRedo)
fd = PathNameOpenFile(path, _mdfd_open_flags());
if (fd < 0)
{
/* be sure to report the error reported by create, not open */
errno = save_errno;
ereport(ERROR,
(errcode_for_file_access(),
errmsg("could not create file \"%s\": %m", path)));
}
}
pfree(path);
_fdvec_resize(reln, forknum, 1);
mdfd = &reln->md_seg_fds[forknum][0];
mdfd->mdfd_vfd = fd;
mdfd->mdfd_segno = 0;
if (!SmgrIsTemp(reln))
register_dirty_segment(reln, forknum, mdfd);
|
所以 mdcrete 的逻辑其实比较简单,如上,主要就是创建第一个文件,通过 PathNameOpenFile 方法创建(或打开)文件并获得文件描述符,然后存储到 SMgrRelation 的 md_seg_fds 数组中。
打开表文件
在函数 smgropen 中,注意这个方法并不会实际去打开文件,只会初始化一些状态。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
| /*
* smgropen() -Return an SMgrRelation object, creating it if need be.
*
* This does not attempt to actually open the underlying file.
*/
SMgrRelation
smgropen(RelFileLocator rlocator, BackendId backend)
{
RelFileLocatorBackend brlocator;
SMgrRelation reln;
bool found;
if (SMgrRelationHash == NULL)
{
/* First time through: initialize the hash table */
HASHCTL ctl;
ctl.keysize = sizeof(RelFileLocatorBackend);
ctl.entrysize = sizeof(SMgrRelationData);
SMgrRelationHash = hash_create("smgr relation table", 400,
&ctl, HASH_ELEM | HASH_BLOBS);
dlist_init(&unowned_relns);
}
/* Look up or create an entry */
brlocator.locator = rlocator;
brlocator.backend = backend;
reln = (SMgrRelation) hash_search(SMgrRelationHash,
&brlocator,
HASH_ENTER, &found);
/* Initialize it if not present before */
if (!found)
{
/* hash_search already filled in the lookup key */
reln->smgr_owner = NULL;
reln->smgr_targblock = InvalidBlockNumber;
for (int i = 0; i <= MAX_FORKNUM; ++i)
reln->smgr_cached_nblocks[i] = InvalidBlockNumber;
reln->smgr_which = 0; /* we only have md.c at present */
/* implementation-specific initialization */
smgrsw[reln->smgr_which].smgr_open(reln);
/* it has no owner yet */
dlist_push_tail(&unowned_relns, &reln->node);
}
return reln;
}
|
如果哈希表 SMgrRelationHash 为空,则初始化
从哈希表中查找表对应的 SMgrRelation 结构
- 如果没找到的话,则初始化一个对应的表文件管理结构体(reln)
- 然后调用磁盘存储管理器(md.c)中的 smgr_open 进行初始化
md 中的 smgr_open 其实也非常简单,只是对 md_num_open_segs 属性进行了初始化。
1
2
3
4
5
6
7
8
9
10
| /*
* mdopen() -Initialize newly-opened relation.
*/
void
mdopen(SMgrRelation reln)
{
/* mark it not open */
for (int forknum = 0; forknum <= MAX_FORKNUM; forknum++)
reln->md_num_open_segs[forknum] = 0;
}
|
关闭表文件
通过函数 mdclose 实现,主要是对每个 Fork 类型的文件,查询 md_seg_fds 中保存的文件描述符信息,然后通过 FileClose 方法关闭文件。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| /*
* mdclose() -Close the specified relation, if it isn't closed already.
*/
void
mdclose(SMgrRelation reln, ForkNumber forknum)
{
int nopensegs = reln->md_num_open_segs[forknum];
/* No work if already closed */
if (nopensegs == 0)
return;
/* close segments starting from the end */
while (nopensegs > 0)
{
MdfdVec *v = &reln->md_seg_fds[forknum][nopensegs 1];
FileClose(v->mdfd_vfd);
_fdvec_resize(reln, forknum, nopensegs 1);
nopensegs--;
}
}
|
删除表文件
在 smgr 中,删除表文件的方法是 smgrdounlinkall,主要会将表文件先关闭(mdclose):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| /*
* create an array which contains all relations to be dropped, and close
* each relation's forks at the smgr level while at it
*/
rlocators = palloc(sizeof(RelFileLocatorBackend) * nrels);
for (i = 0; i < nrels; i++)
{
RelFileLocatorBackend rlocator = rels[i]->smgr_rlocator;
int which = rels[i]->smgr_which;
rlocators[i] = rlocator;
/* Close the forks at smgr level */
for (forknum = 0; forknum <= MAX_FORKNUM; forknum++)
smgrsw[which].smgr_close(rels[i], forknum);
}
|
然后遍历每个 Fork 类型,删除其中的每个文件。
1
2
3
4
5
6
7
| for (i = 0; i < nrels; i++)
{
int which = rels[i]->smgr_which;
for (forknum = 0; forknum <= MAX_FORKNUM; forknum++)
smgrsw[which].smgr_unlink(rlocators[i], forknum, isRedo);
}
|
实际的删除文件流程都在 md.c 中的 mdunlinkfork 方法,删除表文件的时候,会立即删除除了 MAIN_FORK 第 0 个分段文件(Segment)之外的其他文件。
对于 MAIN_FORK 的 0 个文件,会将其保留防止其他表重用文件名,并且将文件内容截取(truncate)到 0,然后发送请求给 checkpointer 进程,让其在下一次 checkpoint 之后再实际删除该文件,关键代码如下:
1
2
3
4
5
6
7
| /* Prevent other backends' fds from holding on to the disk space */
ret = do_truncate(path);
/* Register request to unlink first segment later */
save_errno = errno;
register_unlink_segment(rlocator, forknum, 0 /* first seg */ );
errno = save_errno;
|
扩展表文件
在对数据表文件进行写入时,如果表文件空间不够了,那么需要扩展表文件的大小,通过函数 mdextend 实现。
在扩展时,会以 BLOCK 为单位,每次扩展一个或多个 BLOCK。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| v = _mdfd_getseg(reln, forknum, blocknum, skipFsync, EXTENSION_CREATE);
seekpos = (off_t) BLCKSZ * (blocknum % ((BlockNumber) RELSEG_SIZE));
Assert(seekpos < (off_t) BLCKSZ * RELSEG_SIZE);
if ((nbytes = FileWrite(v->mdfd_vfd, buffer, BLCKSZ, seekpos, WAIT_EVENT_DATA_FILE_EXTEND)) != BLCKSZ)
{
if (nbytes < 0)
ereport(ERROR,
(errcode_for_file_access(),
errmsg("could not extend file \"%s\": %m",
FilePathName(v->mdfd_vfd)),
errhint("Check free disk space.")));
/* short write: complain appropriately */
ereport(ERROR,
(errcode(ERRCODE_DISK_FULL),
errmsg("could not extend file \"%s\": wrote only %d of %d bytes at block %u",
FilePathName(v->mdfd_vfd),
nbytes, BLCKSZ, blocknum),
errhint("Check free disk space.")));
}
if (!skipFsync && !SmgrIsTemp(reln))
register_dirty_segment(reln, forknum, v);
|
大致逻辑是会获得对应的文件描述符,然后通过 FileWrite 方法写入 block 数量大小的数据。
写完之后,会标识该文件是 dirty 的,然后发送请求到 checkpointer 进程(register_dirty_segment),让其在下一次发生 checkpoint 的时候将文件内容落盘。
读写表文件
读写表文件中的 block 主要是通过 mdread/mdwrite 方法。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| /*
* mdread() -Read the specified block from a relation.
*/
void
mdread(SMgrRelation reln, ForkNumber forknum, BlockNumber blocknum,
void *buffer)
{
off_t seekpos;
int nbytes;
MdfdVec *v;
/* If this build supports direct I/O, the buffer must be I/O aligned. */
if (PG_O_DIRECT != 0 && PG_IO_ALIGN_SIZE <= BLCKSZ)
Assert((uintptr_t) buffer == TYPEALIGN(PG_IO_ALIGN_SIZE, buffer));
TRACE_POSTGRESQL_SMGR_MD_READ_START(forknum, blocknum,
reln->smgr_rlocator.locator.spcOid,
reln->smgr_rlocator.locator.dbOid,
reln->smgr_rlocator.locator.relNumber,
reln->smgr_rlocator.backend);
v = _mdfd_getseg(reln, forknum, blocknum, false,
EXTENSION_FAIL | EXTENSION_CREATE_RECOVERY);
seekpos = (off_t) BLCKSZ * (blocknum % ((BlockNumber) RELSEG_SIZE));
Assert(seekpos < (off_t) BLCKSZ * RELSEG_SIZE);
nbytes = FileRead(v->mdfd_vfd, buffer, BLCKSZ, seekpos, WAIT_EVENT_DATA_FILE_READ);
}
|
读取的时候,会传入表文件的 SMgrRelation 结构体,以及文件类型 forknum 和块号 blocknum,然后通过 FileRead 方法将数据读取到指定的 buffer 中。
mdwrite 的方法和读取基本类似,主要是将指定的 buffer 内容通过 FileWrite 方法写入到对应的文件中。
1
2
3
4
5
6
7
8
| v = _mdfd_getseg(reln, forknum, blocknum, skipFsync,
EXTENSION_FAIL | EXTENSION_CREATE_RECOVERY);
seekpos = (off_t) BLCKSZ * (blocknum % ((BlockNumber) RELSEG_SIZE));
Assert(seekpos < (off_t) BLCKSZ * RELSEG_SIZE);
nbytes = FileWrite(v->mdfd_vfd, buffer, BLCKSZ, seekpos, WAIT_EVENT_DATA_FILE_WRITE);
|
注意这里写入之后,并不会等待操作系统刷盘之后再返回,而是直接返回,将刷盘的请求交给了 checkpointer 进程,由此来提高数据写入的效率,而数据的崩溃恢复、一致性,是通过 WAL 来保证的。