前面一节主要从宏观上了解 Postgres 表数据文件的组织方式,接下来我们深入到一个表文件的 page 内部,查看 page 的具体结构表示。
存储在磁盘上的一个表数据文件,内部切分为了多个 page,每个 page 默认的大小是 8KB,为了从磁盘上读取数据的效率,每次从文件中读取数据的时候,都是以 page 作为基本单位。
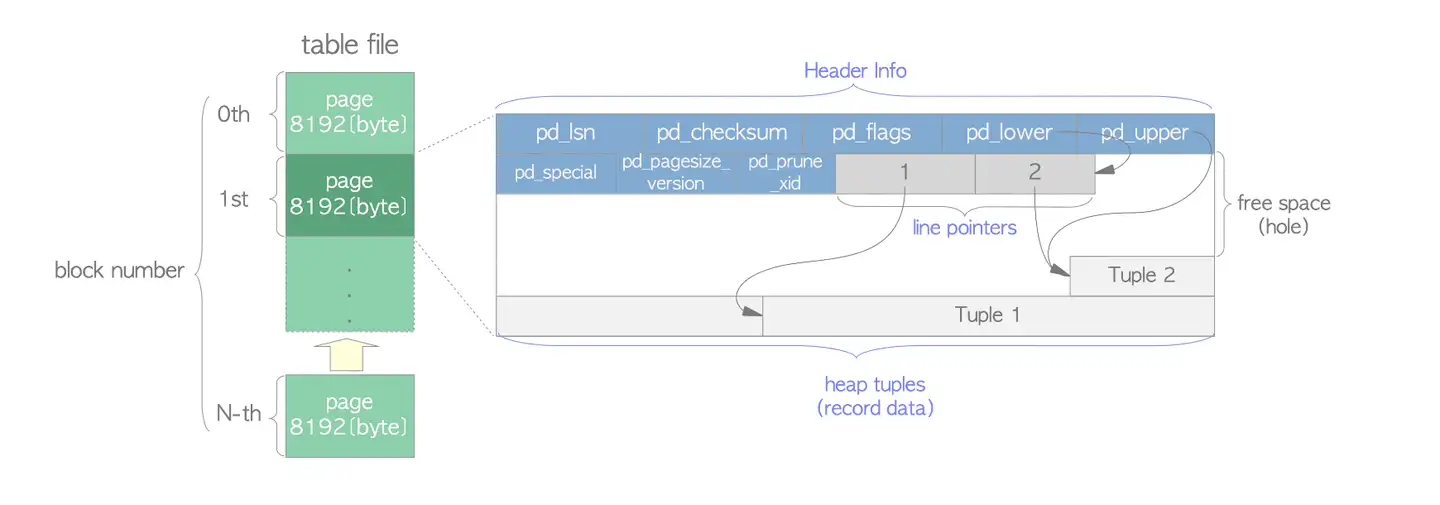
文件页中的每个 Page 被赋予了一个连续递增的唯一的编号,叫做 BlockNumber。
| |
我们可以通过 Postgres 的插件 pageinspect 来查看一个 page 的内部结构和状态。
| |
我这里创建了一个对应的插件,并且创建了一个表。
然后可以通过 pageinspect 插件的一些函数查看表所属的 page 的数据信息:
| |
get_raw_page 是插件实现的方法,接收两个参数,分别是表名和 page 编号;page_header 方法则可以获取到 page 的 Header 头部信息。
可以看到获取到的字段和下图的 PageHeader 结构基本一致。
每个 page 主要由页头、内容、special 三部分组成,大致物理存储结构如下所示:
| |
页头部分其实是这个 page 的一些元数据信息,由 PageHeaderData 结构体表示,主要有如下内容:
pd_lsn:xlog(WAL) 在当前 page 的最后一次修改的日志记录
pd_checksum:文件页对应的校验和,保护文件页内容
pd_flags:page 的一些状态信息,取值有如下几种
#define PD_HAS_FREE_LINES 0x0001 /* are there any unused line pointers? / #define PD_PAGE_FULL 0x0002 / not enough free space for new tuple? / #define PD_ALL_VISIBLE 0x0004 / all tuples on page are visible to * everyone / #define PD_VALID_FLAG_BITS 0x0007 / OR of all valid pd_flags bits */
PD_HAS_FREE_LINES:是否还有未使用的 linp 指针
PD_PAGE_FULL:页面已满,剩余的空间无法容纳新的 Tuple
PD_ALL_VISIBLE:page 所有的 tuple 都是可见的
PD_VALID_FLAG_BITS:全部有效的 pd_flags 标记位
pd_lower:该 page 内空闲空间的起始位置
pd_upper:该 page 内空闲空间的结束位置
pd_special:存储一些特定的信息,比如 BTree 索引会用到
pd_pagesize_version:存储页面大小和版本信息
pd_prune_xid:page 中可删除的最旧的事务 ID
pd_linp:即前面注释中标注的 linp 1 linp 2 linp 3 … Linp n,是一个数组,用来标识 page 内一条数据的位置偏移,使用结构体 ItemIdData 表示。
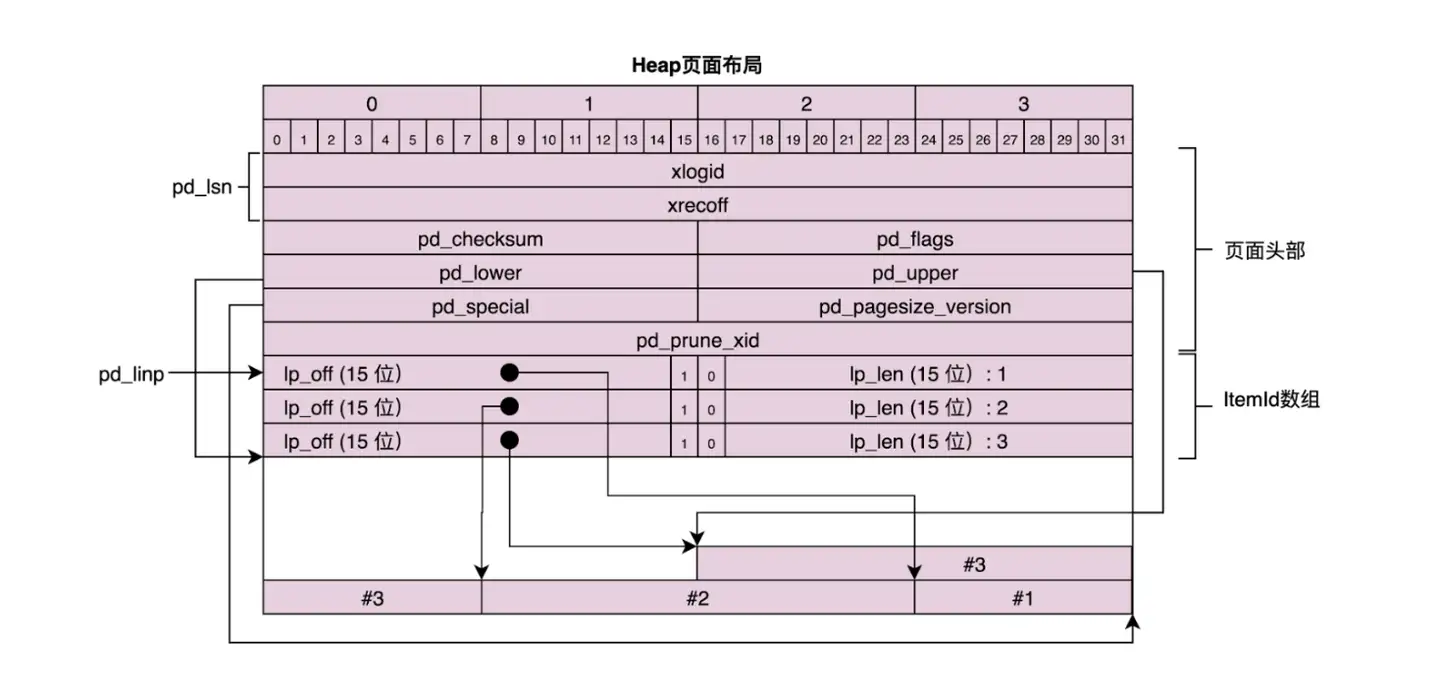
ItemIdData 结构体主要有三个字段:
| |
lp_off 占 15 位,表示数据在 page 的偏移
lp_flags 占 2 位,表示状态,取值有这几种:
/* * lp_flags has these possible states. An UNUSED line pointer is available * for immediate re-use, the other states are not. / #define LP_UNUSED 0 / unused (should always have lp_len=0) / #define LP_NORMAL 1 / used (should always have lp_len>0) / #define LP_REDIRECT 2 / HOT redirect (should have lp_len=0) / #define LP_DEAD 3 / dead, may or may not have storage */
LP_UNUSED:表示此空间空闲,未被使用
LP_NORMAL:指向实际的偏移位置
LP_REDIRECT:不指向实际数据,而是一个跳转,指向其他的 ItemIdData,用于 HOT(Heap Only Tuple)
LP_DEAD:数据已经被删除
lp_length:数据的长度
从前面的 page 结构描述中可以得知,一条 Tuple 在插入到 page 当中的时候,是无序的,所以 Postgres 中最常用的表组织方式叫做 Heap,意为杂乱的,无顺序的。
这种数据组织的方式,其实可以非常高效的读取、插入、删除表中的一行数据,因此 Postgres 的 Heap 表结构其实适用于 OLTP 的场景。
当读取数据的时候,可以根据 BlockNumber 确定 page 编号,以及页内偏移 OffsetNumber 确定数据在 page 内的位置,使用结构体 ItemPointerData 表示一条数据的物理存储位置。
| |
参考资料